ServerLoadSpreading
Note: You are viewing an old revision of this page. View the current version.
Like Peanut Butter on Toast
Say you have a process that runs on lots and lots of servers and you want to make sure it doesn't execute on every machine at the same time. What's the best way to design that setup?
I had to implement a system like this at my work. In this case we had about 10,000 servers and an update process that had to run once per day per machine. My first guess at how to implement load spreading was by using something simple like the bash $RANDOM pseudorandom number generator. But, is that sufficient to adequately spread the load? I started thinking about other alternatives and hit on the idea of using a hashing function. I then decided to take the next step and try to compare the two methods empirically. The rest of this post explains that process and my conclusions.
large numbers of servers contacting a central host
some thoughts on using a perl hash function instead of a random delay
use B;
sub compute_hash
{
my ($string,$range) = @_;
my $hc = hex(B::hash $string);
return $hc % $range + 1;
}
reference: http://www.perlmonks.org/index.pl?node_id=315876
how hashes really work: http://www.perl.com/pub/2002/10/01/hashes.html
calling the perl has function: http://www.perlmonks.org/?node_id=229982
more than you could ever want to know about hashing: http://burtleburtle.net/bob/hash/doobs.html
another hash function that probably isn't very good:
sub compute_hash
{
my ($string,$low,$high) = @_;
my $hc = 0;
my $i = 0;
my $range = ($high - $low) + 1;
while ($i < length($string))
{
$hc = ((($hc) >> 27) | (($hc) << 5)) ^ ord(substr($string,$i++,1));
}
$hc = ((($hc) >> 1) | (($hc) << 31)) ^ ($hc);
$hc = ((($hc) >> 3) | (($hc) << 29)) ^ ($hc);
$hc = ((($hc) >> 5) | (($hc) << 27)) ^ ($hc);
$hc = ((($hc) >> 7) | (($hc) << 25)) ^ ($hc);
$hc = ((($hc) >> 9) | (($hc) << 23)) ^ ($hc);
$hc = ((($hc) >> 11) | (($hc) << 21)) ^ ($hc);
$hc = ((($hc) >> 13) | (($hc) << 19)) ^ ($hc);
$hc = ((($hc) >> 15) | (($hc) << 17)) ^ ($hc);
return $low + ($hc % $range);
}
need to do some distribution tests against a corpus of common hostnames or something like that.
why you should use a hash instead of a random delay? 1. Repeatable delay for each host. 2. maybe better guarantee of spread?
to test: on each remote host run this:
perl -le "print int rand(86400)+1"
would be interesting to compare these delays to the spread generated by calling bash RANDOM.
for bash , run this on remote host:
expr $RANDOM \* 3 % 86400 + 1'
#!/usr/bin/perl
# randomer.pl
# process input in form of
# <hostname> <delay>
#
#and transform into
#
# <delay> <count>
#
# suitable for frequency plotting.
use warnings;
use strict;
my %counter = ();
while(<>)
{
(my $delay) = (/^\S+\s+(\S+)/);
$counter{$delay}++;
}
foreach (sort {$a<=>$b} keys %counter)
{
print $_ . " " . $counter{$_} . "\n";
}
results in output like this:
1 1 2 1 3 1 7 1 30 1 42 1 47 1 49 1 66 1 71 1 96 1 112 1 126 1 134 1 136 1 140 1
etc.
gnuplot control file:
set terminal png size 1000,300 font "/Library/Fonts/Andale Mono.ttf" 12 set output "spread.png" set xrange [0:86400] set yrange [0:4] set xlabel "delay (s)" set ylabel "# of hosts" set title "collisions using perl \"int(rand())\" for delay value - 9313 hosts, 86400s spread" set ytics 1 set xtics nomirror set ytics nomirror set key off plot "random-freq.txt" using 1:2 index 0 title "number of collisions" pt 6 lt 2
output of perl hashed approach:

collision counts:
9047 hosts no collisions
540 hosts one collision
13 hosts two collisions
no hosts more than two collisions
output of bash random approach:
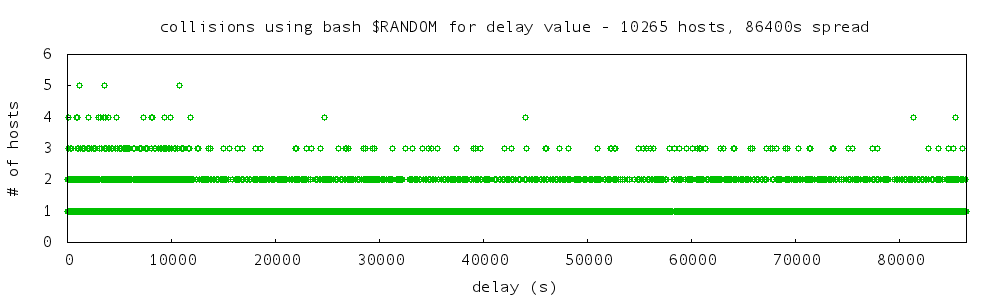
collision counts:
6989 hosts no collisions
1314 hosts one collision
183 hosts two collisions
21 hosts three collisions
3 hosts four collisions
no hosts more than four collisionst

